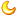|
|
<
导读
做者:Gopal Shankar
翻译:缓朝明 本文地点: https://mysqlserverteam.com/mysql-8-0-improvements-to-information_schema/
Coinciding with the new native data dictionary in MySQL 8.0, we have made a number of useful enhancements to our INFORMATION_SCHEMA subsystem design in MySQL 8.0. In this post I will first go through our legacy implementation as it has stood since MySQL 5.1, and then cover what’s changed. 取MySQL 8.0本死数据字典分歧,正在MySQL 8.0的 INFORMATION_SCHEMA 子体系设想中,我们做了一些很有效的加强。正在那篇文章中,我将会引见自MySQL 5.1以去的旧的完成方法,然后引见我们做了甚么改动。 Background INFORMATION_SCHEMA was first introduced into MySQL 5.0, as a standards compliant way of retrieving meta data from a running MySQL server. When we look at the history of INFORMATION_SCHEMA there have been a number of complaints about the performance of certain queries, particularly in the case that there are many database objects (schemas, tables etc). INFORMATION_SCHEMA 初次引进MySQL 5.0,做为一种从正正在运转的MySQL效劳器检索元数据的标准兼容方法。当我们回忆 INFORMATION_SCHEMA 的汗青时,关于某些特定查询机能老是有许多的埋怨,出格是正在有很多数据库工具(schema,表等)的状况下。 In an effort to address these reported issues, since MySQL 5.1 we have made a number of performance optimizations to speed up the execution of INFORMATION_SCHEMA queries. The optimizations are described in the MySQL manual, and apply when the user provides an explicit schema name or table name in the query. 为了打点那些上报的成绩,从MySQL 5.1开端,我们举办了很多机能劣化去放慢 INFORMATION_SCHEMA 查询的施行速率。MySQL脚册 中形貌了那些劣化,当用户正在查询中供给隐式schema称号或表名时,将会使用那些。 Alas, despite these improvements INFORMATION_SCHEMA performance is still a major pain point for many of our users. The key reason behind these performance issues in the current INFORMATION_SCHEMA implementation is that INFORMATION_SCHEMA tables are implemented as temporary tables that are created on-the-fly during query execution. These temporary tables are populated via:
- Meta data from files, e.g. table definitions from .FRM files.
- Details from storage engines, e.g. dynamic table statistics.
- Data from global data structures in the MySQL server.
虽然有那些改良, INFORMATION_SCHEMA的 机能仍旧是我们很多用户的次要痛面。正在当前 INFORMATION_SCHEMA 完成方法下发生的机能成绩背后的枢纽缘故原由是, INFORMATION_SCHEMA 表的查询完成方法是正在查询施行时期创立临时表。那些临时表经由过程以下方法添补:
- 元数据去自文件,比方:表界说去自FRM文件
- 细节去自于存储引擎,比方:静态表的统计疑息
- 去自MySQL server层中齐局数据规划的数据
For a MySQL server having hundreds of database, each with hundreds of tables within them, the INFORMATION_SCHEMA query would end-up doing lot of I/O reading each individual FRM files from the file system. And it would also end-up using more CPU cycles in effort to open the table and prepare related in-memory data structures. It does attempt to use the MySQL server table cache (the system variable ‘ table_definition_cache ‘), however in large server instances it’s very rare to have a table cache that is large enough to accommodate all of these tables. 关于一个MySQL真例来讲能够有上百个库,每一个库又有上百张表, INFORMATION_SCHEMA 查询终极会从文件体系中读与每一个零丁的FRM文件,形成许多I/O读与。 并且终极借会耗损更多的CPU去翻开表并筹办相干的内乱存数据规划。 它的确测验考试利用MySQL server层的表缓存(体系变量 table_definition_cache ),可是正在年夜型真例中,很少有一个充足年夜的表缓存去包容一切的表。 One can easily face the above mentioned performance issue if the optimization is not used by the INFORMATION_SCHEMA query. For example, let us consider the two queries below 假如 INFORMATION_SCHEMA 查询已利用劣化,则能够很简单碰着上里的机能成绩。 比方,让我们考虑上面的两个查询
- [/code] mysql > EXPLAIN SELECT TABLE_NAME FROM INFORMATION_SCHEMA. TABLES WHERE
- -> TABLE_SCHEMA = 'test' AND TABLE_NAME = 't1'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: TABLES
- partitions: NULL
- type: ALL
- possible_keys: NULL
- key: TABLE_SCHEMA,TABLE_NAME
- key_len: NULL
- ref: NULL
- rows: NULL
- filtered: NULL
- Extra: Using where; Skip_open_table; Scanned 0 databases
- 1 row in set, 1 warning ( 0. 00 sec)
-
- mysql > EXPLAIN SELECT TABLE_NAME FROM INFORMATION_SCHEMA. TABLES WHERE
- -> TABLE_SCHEMA like 'test%' AND TABLE_NAME like 't%'\G
- *************************** 1. row ***************************
- id: 1
- select_type: SIMPLE
- table: TABLES
- partitions: NULL
- type: ALL
- possible_keys: NULL
- key: NULL
- key_len: NULL
- ref: NULL
- rows: NULL
- filtered: NULL
- Extra: Using where; Skip_open_table; Scanned all databases
- 1 row in set, 1 warning ( 0. 00 sec)
- As we can see from the EXPLAIN output, we see that the former query would use the values provided in WHERE clause for the TABLE_SCHEMA and TABLE_NAME field as a key to read the desired FRM files from the file system. However, the latter query would end up reading all the FRM in the entire data directory, which is very costly and does not scale. 从 EXPLAIN 的输出能够看到。 我们看到前一个查询将利用 WHERE 子句中为 TABLE_SCHEMA 战 TABLE_NAME 字段供给的值做为键,从文件体系读与所需 FRM 文件。 可是,后一个查询终极将读与全部数据目次中的一切 FRM ,那十分高贵且没法扩大。
- Changes in MySQL 8.0
- One of the major changes in 8.0 is the introduction of a native data dictionary based on InnoDB. This change has enabled us to get rid of file-based metadata store ( FRM files) and also help MySQL to move towards supporting transactional DDL. For more details on introduction of data dictionary feature in 8.0 and its benefits, please look at Staale’s post here. 8.0中的一个次要变革是引进了基于InnoDB的数据字典。那一变革使我们可以挣脱基于文件的元数据存储( FRM 文件),并赞助MySQL转背撑持事件DDL。有闭正在8.0中引进数据字典功用及其长处的更多具体疑息,请正在此处检察Staale的文章 。 Now that the metadata of all database tables is stored in transactional data dictionary tables, it enables us to design an INFORMATION_SCHEMA table as a database VIEW over the data dictionary tables. This eliminates costs such as the creation of temporary tables for each INFORMATION_SCHEMA query during execution on-the-fly, and also scanning file-system directories to find FRM files. It is also now possible to utilize the full power of the MySQL optimizer to prepare better query execution plans using indexes on data dictionary tables. 既然一切数据库表的元数据皆存储正在事件数据字典表中,它使我们可以将INFORMATION_SCHEMA表设想为数据字典表上的数据库视图 。 那消弭了本钱,比方正在施行时期为每一个 INFORMATION_SCHEMA 查询创立临时表,和扫描文件体系目次以查找FRM文件。 如今借可使用MySQL劣化器的局部功用,利用数据字典表上的索引去获得更好的施行方案。 The following diagram explains the difference in design in MySQL 5.7 and 8.0. 上面的图注释了MySQL 5.7战8.0设想上的区分 [align=center]
[/align] If we consider the above example under Background, we see that the optimizer plans to use indexes on data dictionary tables, in both the cases. 假如我们正在之前引见的布景下考虑上里的例子,我们会看到劣化器正在两种状况下城市利用数据字典表上的索引。
- [code]
+ --+-----------+-----++------+------------------+----------++----------------------+----+--------+----------------------------------+
|id|select_type|table ||type |possible_keys |key ||ref |rows|filtered|Extra |
+ --+-----------+-----++------+------------------+----------++----------------------+----+--------+----------------------------------+
| 1|SIMPLE |cat ||index |PRIMARY |name ||NULL | 1| 100. 00|Using index |
| 1|SIMPLE |sch ||eq_ref|PRIMARY,catalog_id|catalog_id || mysql. cat.id,const | 1| 100. 00|Using index |
| 1|SIMPLE |tbl ||eq_ref|schema_id |schema_id || mysql. sch.id,const | 1| 10. 00|Using index condition; Using where|
| 1|SIMPLE |col ||eq_ref|PRIMARY |PRIMARY || mysql. tbl.collation_id| 1| 100. 00|Using index |
+ --+-----------+-----++------+------------------+----------++----------------------+----+--------+----------------------------------+
mysql > EXPLAIN SELECT TABLE_NAME FROM INFORMATION_SCHEMA. TABLES WHERE TABLE_SCHEMA like 'test%' AND TABLE_NAME like 't%';
+ --+-----------+-----++------+------------------+----------++-----------------------+----+--------+---------------------------------+
|id|select_type|table ||type |possible_keys |key || ref |rows|filtered|Extra |
+ --+-----------+-----++------+------------------+----------++-----------------------+----+--------+---------------------------------+
| 1|SIMPLE |cat ||index |PRIMARY |name || NULL | 1| 100. 00|Using index |
| 1|SIMPLE |sch ||ref |PRIMARY,catalog_id|catalog_id || mysql. cat.id | 6| 16. 67|Using where; Using index |
| 1|SIMPLE |tbl ||ref |schema_id |schema_id || mysql. sch.id | 26| 1. 11|Using index condition;Using where|
| 1|SIMPLE |col ||eq_ref|PRIMARY |PRIMARY || mysql. tbl.collation_id| 1| 100. 00|Using index |
+ --+-----------+-----++------+------------------+----------++-----------------------+----+--------+---------------------------------+
When we look at performance gain with this new INFORMATION_SCHEMA design in 8.0, we see that it is much more efficient than MySQL 5.7. As an example, this query is now ~100 times faster (with 100 databases with 50 tables each). A separate blog will describe more about performance of INFORMATION_SCHEMA in 8.0. 当我们经由过程那个齐新的8.0设想的 INFORMATION_SCHEMA 去看机能提拔时,我们发明它比MySQL 5.7更有用。 比方,此查询如今快〜100倍(100个数据库,每一个50个表)。 别的一篇专客将具体引见8.0 中 INFORMATION_SCHEMA 机能 。
[code][/code] SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_TYPE, ENGINE, ROW_FORMAT
FROM information_schema. tables
WHERE TABLE_SCHEMA LIKE 'db%'; Sources of Metadata
Not all the INFORMATION_SCHEMA tables are implemented as a VIEW over the data dictionary tables in 8.0. Currently we have the following INFORMATION_SCHEMA tables designed as views: 并不是一切 INFORMATION_SCHEMA 表皆经由过程8.0中的数据字典表做为视图完成。 今朝,我们将以下 INFORMATION_SCHEMA 表设想为视图:
- SCHEMATA
- TABLES
- COLUMNS
- VIEWS
- CHARACTER_SETS
- COLLATIONS
- COLLATION_CHARACTER_SET_APPLICABILITY
- STATISTICS
- KEY_COLUMN_USAGE
- TABLE_CONSTRAINTS
Upcoming MySQL 8.0 versions aims to provide even the following INFORMATION_SCHEMA tables as views: 行将推出的MySQL 8.0版本将供给以下 INFORMATION_SCHEMA 表做为视图:
- EVENTS
- TRIGGERS
- ROUTINES
- REFERENTIAL_CONSTRAINTS
To describe the INFORMATION_SCHEMA queries which are not directly implemented as VIEWs over data dictionary tables, let me first describe that there are two types of meta data which are presented in INFORMATION_SCHEMA tables: 为了形貌INFORMATION_SCHEMA查询,那些查询出有间接完成为数据字典表上的视图, 让我起首形貌正在 INFORMATION_SCHEMA 表中有两品种型的元数据:
- Static table metadata. For example: TABLE_SCHEMA , TABLE_NAME , TABLE_TYPE , ENGINE . These statistics will be read directly from the data dictionary.
- Dynamic table metadata. For example: AUTO_INCREMENT , AVG_ROW_LENGTH , DATA_FREE . Dynamic metadata frequently changes (for example: the auto_increment value will advance after each insert).In many cases the dynamic metadata will also incur some cost to accurately calculate on demand, and accuracy may not be beneficial for the typical query. Consider the case of the DATA_FREE statistic which shows the number of free bytes in a table – a cached value is usually sufficient.
- 静态表元数据。 比方: TABLE_SCHEMA , TABLE_NAME , TABLE_TYPE , ENGINE 。 那些静态数据将会从数据字典中间接读与
- 静态表元数据。 比方: AUTO_INCREMENT , AVG_ROW_LENGTH , DATA_FREE 。 静态元数据常常会变动(比方: 自删值会正在每次插进后自删)。 正在很多状况下,静态元数据也会发生一些本钱,以便按需精确计较,并且关于某些特定的查询那个精确性并出有效。 考虑 DATA_FREE 统计疑息的状况,该统计疑息显现表中的闲暇字节数 - 缓存值凡是便充足了。
In MySQL 8.0, the dynamic table metadata will default to being cached. This is configurable via the setting information_schema_stats (default cached ), and can be changed to information_schema_stats=latest in order to always retrieve the dynamic information directly from the storage engine (at the cost of slightly higher query execution). 正在MySQL 8.0中,静态表元数据将默许为缓存。 那能够经由过程设置 information_schema_stats (默许 缓存 )举办设置,并且能够变动为 information_schema_stats = latest ,以便一直间接从存储引擎检索静态疑息(以稍下的查询施行为价格) As an alternative, the user can also execute ANALYZE TABLE on the table, to update the cached dynamic statistics. 做为替换计划,用户借能够正在表 上施行 ANALYZE TABLE ,以更新缓存的静态统计疑息。
Conclusion
The INFORMATION_SCHEMA design in 8.0 is a step forward enabling:
- Simple and maintainable implementation.
- Us to get rid of numerous INFORMATION_SCHEMA legacy bugs.
- Proper use of the MySQL optimizer for INFORMATION_SCHEMA queries.
- INFORMATION_SCHEMA queries to execute ~100 times faster, compared to 5.7, when retrieving static table metadata, as show in query Q1.
8.0中的 INFORMATION_SCHEMA 设想是背前迈出的一步:
- 俭朴且可保护的完成。
- 我们挣脱了许多的 INFORMATION_SCHEMA 遗留缺点。
- 准确利用MySQL劣化器举办 INFORMATION_SCHEMA 查询。
- 取检索静态表元数据时的5.7比拟, INFORMATION_SCHEMA 查询施行速率快~100倍,如查询Q1中所示。
There is more to discuss about INFORMATION_SCHEMA in 8.0. The new implementation comes with a few changes in behavior when compared to the old INFORMATION_SCHEMA implementation. Please check the MySQL manual for more details about it. Thanks for using MySQL! 正在8.0中另有更多闭于 INFORMATION_SCHEMA的 会商。 取旧的 INFORMATION_SCHEMA 完成比拟,新的完成方法有一些变革。 有闭它的更多具体疑息,请检察MySQL脚册。 感激您利用MySQL!
链接1: http://dev.mysql.com/doc/refman/5.7/en/information-schema-optimization.html 链接2: http://mysqlserverteam.com/a-new-data-dictionary-for-mysql/
END
扫码参加MySQL手艺Q群
(群号:529671799)
免责声明:假如进犯了您的权益,请联络站少,我们会实时删除侵权内乱容,感谢协作! |
1、本网站属于个人的非赢利性网站,转载的文章遵循原作者的版权声明,如果原文没有版权声明,按照目前互联网开放的原则,我们将在不通知作者的情况下,转载文章;如果原文明确注明“禁止转载”,我们一定不会转载。如果我们转载的文章不符合作者的版权声明或者作者不想让我们转载您的文章的话,请您发送邮箱:Cdnjson@163.com提供相关证明,我们将积极配合您!
2、本网站转载文章仅为传播更多信息之目的,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证信息的正确性和完整性,且不对因信息的不正确或遗漏导致的任何损失或损害承担责任。
3、任何透过本网站网页而链接及得到的资讯、产品及服务,本网站概不负责,亦不负任何法律责任。
4、本网站所刊发、转载的文章,其版权均归原作者所有,如其他媒体、网站或个人从本网下载使用,请在转载有关文章时务必尊重该文章的著作权,保留本网注明的“稿件来源”,并自负版权等法律责任。
|
 代码
1297 人阅读
|
0 人回复
代码
1297 人阅读
|
0 人回复