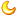|
|
<
近来碰上一个需供,需求给物流行业的Excel婚配派收费,详细完好需供较为庞大。此中触及的一个费事面能够拿出去给大家讲讲。
那些物流定单表中,经由过程持续不异的色彩标识属于开票派收,其实不像数据库有零丁的字段标识表记标帜。明天我们的完成目的是读与持续不异的色彩,标识表记标帜统一个分组编号。
经由过程openpyxl读与xlsx格局的色彩比力简朴没有做演示了,读者也能够思索先将xls格局先转换为xlsx格局再读与色彩。不外我明天演示的是利用xlrd库间接读与xls格局的Excel表,从而剖析出色彩,并阐发能否是持续不异的色彩,给一个独一的分组编号。
举个例子,关于以下Excel表:
那4个色彩持续不异的的单位格,标识表记标帜为统一个编号。
起首我们读与那个Excel表:
- import xlrd
- # 翻开Excel,为了读与款式疑息需求指定formatting_info=True
- book = xlrd.open_workbook("test.xls", formatting_info=True)
- # 获得第一张sheet
- sheet = book.sheets()[0]
- sheet
- [/code] 起首我们先尝试读与第一个有色彩的单位格:
- [code]cell = sheet.cell(2, 1)
- print(cell.value, cell.xf_index)
**那末假如按照索引获得色彩值呢?**这时候需求利用齐局色彩界说表:
- colour_index = book.xf_list[cell.xf_index].background.pattern_colour_index
- book.colour_map[colour_index]
- def get_cell_color(cell):
- colour_index = book.xf_list[cell.xf_index].background.pattern_colour_index
- return book.colour_map[colour_index]
- get_cell_color(sheet.cell(8, 1))
**怎样批量读与数据?**利用get_rows天生器最简朴:
- import pandas as pd
- rows = sheet.get_rows()
- header = [cell.value for cell in next(rows)]
- data = []
- for row in rows:
- data.append([cell.value for cell in row])
- df = pd.DataFrame(data, columns=header)
- df.head(20)
基于以上代码,上面我们批量读与全部Excel的数据,并按照色彩值付与一个开票编号:
- import pandas as pd
- rows = sheet.get_rows()
- header = [cell.value for cell in next(rows)]
- header.append("开票编号")
- data = []
- last_color = None
- num = 0
- for row in rows:
- t = [cell.value for cell in row]
- color = get_cell_color(row[1])
- if color and color != (255, 255, 255):
- if color != last_color:
- num += 1
- t.append(num)
- else:
- t.append(pd.NA)
- last_color = color
- data.append(t)
- df = pd.DataFrame(data, columns=header)
- df.head(20)
如许我们便处理了那个成绩。完好代码以下:
- import pandas as pd
- import xlrd
- def get_cell_color(cell):
- colour_index = book.xf_list[cell.xf_index].background.pattern_colour_index
- return book.colour_map[colour_index]
- # 翻开Excel,为了读与款式疑息需求指定formatting_info=True
- book = xlrd.open_workbook("test.xls", formatting_info=True)
- # 获得第一张sheet
- sheet = book.sheets()[0]
- rows = sheet.get_rows()
- header = [cell.value for cell in next(rows)]
- header.append("开票编号")
- data = []
- last_color = None
- num = 0
- for row in rows:
- t = [cell.value for cell in row]
- color = get_cell_color(row[1])
- if color and color != (255, 255, 255):
- if color != last_color:
- num += 1
- t.append(num)
- else:
- t.append(pd.NA)
- last_color = color
- data.append(t)
- df = pd.DataFrame(data, columns=header)
- df
免责声明:假如进犯了您的权益,请联络站少,我们会实时删除侵权内乱容,感谢协作! |
1、本网站属于个人的非赢利性网站,转载的文章遵循原作者的版权声明,如果原文没有版权声明,按照目前互联网开放的原则,我们将在不通知作者的情况下,转载文章;如果原文明确注明“禁止转载”,我们一定不会转载。如果我们转载的文章不符合作者的版权声明或者作者不想让我们转载您的文章的话,请您发送邮箱:Cdnjson@163.com提供相关证明,我们将积极配合您!
2、本网站转载文章仅为传播更多信息之目的,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证信息的正确性和完整性,且不对因信息的不正确或遗漏导致的任何损失或损害承担责任。
3、任何透过本网站网页而链接及得到的资讯、产品及服务,本网站概不负责,亦不负任何法律责任。
4、本网站所刊发、转载的文章,其版权均归原作者所有,如其他媒体、网站或个人从本网下载使用,请在转载有关文章时务必尊重该文章的著作权,保留本网注明的“稿件来源”,并自负版权等法律责任。
|
 代码
1680 人阅读
|
0 人回复
代码
1680 人阅读
|
0 人回复