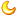接着爬虫系列,担当讲解XPath定位
老司机,带您用30止代码爬与下浑美女写实,附装置包+源码
真操绝:爬虫根底常识,阅读器最底子的设置办法
真操绝:HTML底子规划,和数据根源,网页获得
明天担当讲解XPath定位
1、XPath曲不雅考证东西 selenium IDE
结果展现
以百度为例,获得一切 div带id属性 的元素,被选中的正在HTML背影色减深,正在网页中有实线边框
selenium IDE装置
1 .下载水狐55之内版本装置包(最新版本曾经没有撑持了),装置完成,疾速设置抑制主动更新版本
2 .下载selenium IDE,FireXPath,firebug离线包
3 .顺次把离线包拖进阅读器
4 .装置胜利后,面击左上角的小虫子
5 .由于网盘简单生效,离线包资本放正在群同享了
XPath格局
//div[@id]
第一部门,从那里获得,须要
/表示从跟节面获得
//表示从当前节面下获得节面,没有考虑中心层级干系
比方:
//div [@id=“content_left”]/div只会获得全部左边div标签尾层div
//div [@id=“content_left”]//div会获得全部左边div标签
第两部门,标署名称,须要
常睹块标签div,p,ul,ol
通配符*表示一切标签
第三部门,[ ]表达式润饰符,非须要
润饰符必需共同,表达式一同利用,不然报错
第四部门,@属性挑选
常睹属性id,class
from表单中的name,a标签内里的title也能够做属性挑选
XPath内乱置表达式
需求写正在[ ]内里
撑持比较运算符,=,>,</h2 h3a id="idu_70"/a属性比较//*[@id=’u’]/h3 pimg src="https://img-blog.csdnimg.cn/a7b559566c9f45c098f7942982fe2899.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5rS-5qOu5pS75Z-O54uu,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center" alt="正在那里插进图片形貌" / /p h3a id="3a_aposition3_75"/a与前3以后的a标签 //a[position()>3]
撑持逻辑运算and战or,not( )
//*[@id=‘container’ or @id=‘u’]
别的正在介绍两个定位函数
preceding-sibling::*定位兄弟元素
//[@id=‘u’]/preceding-sibling::
…定位女元素
//*[@id=‘u’]/…
总结:
1.利用XPath东西,有助于您快速定位元素
2.能够借助XPath东西,考证本人写出写对
3.专主正在进修时期珍藏了很多适用的小东西,文件比较多,放正在群同享了
免责声明:假如进犯了您的权益,请联络站少,我们会实时删除侵权内乱容,感谢协作! |  代码
1308 人阅读
|
0 人回复
代码
1308 人阅读
|
0 人回复